Comment fonctionnent les moteurs de recherche – Analyse, indexation et classement
Les moteurs de recherche sont des “machines à réponses”. Ils existent pour découvrir, comprendre et organiser le contenu d’Internet afin d’offrir les résultats les plus pertinents aux questions posées par les internautes.
Afin de figurer dans les résultats de recherche, votre contenu doit d’abord être visible pour les moteurs de recherche. C’est sans doute la pièce la plus importante du puzzle SEO: si votre site ne peut pas être trouvé, vous ne vous retrouverez jamais dans les Search Engine Results Pages, SERP,(page des résultats des moteurs de recherche).
Comment fonctionnent les moteurs de recherche ?
Les moteurs de recherche ont trois fonctions principales:
- Crawl: Les robots comme les Google bots par exemple, vont parcourir Internet à la recherche de contenu et examiner le code / contenu de chaque URL trouvée.
- Index: Le moteur de recherche va alors stocker et organiser le contenu trouvé lors du processus d’analyse. Une fois qu’une page est dans l’index, elle est affichée pour répondre aux requêtes pertinentes.
- Rank: Il fournit les éléments de contenu qui répondront le mieux à la requête d’un chercheur. Commandez les résultats de la recherche par les plus utiles pour une requête particulière.
Qu’est-ce que le crawling par les moteurs de recherche ?
Le crawling est le processus de découverte dans lequel les moteurs de recherche envoient une équipe de robots (ou robots) pour trouver du contenu nouveau et mis à jour. Le contenu peut varier – il peut s’agir d’une page Web, d’une image, d’une vidéo, d’un fichier PDF, etc. – mais quel que soit le format, le contenu est découvert par des liens présents sur Internet.
Le bot commence par récupérer quelques pages Web, puis suit les liens sur ces pages Web pour trouver de nouvelles URL. En parcourant ces liens, les bots d’exploration peuvent trouver du nouveau contenu et l’ajouter à leur index – pour être récupéré ultérieurement lorsqu’un internaute cherche à savoir si le contenu de cette URL correspond bien .
Qu’est-ce que l’indexation de moteur de recherche?
Les moteurs de recherche traitent et stockent les informations qu’ils trouvent dans un index, une énorme base de données de tout le contenu qu’ils ont découvert et jugent suffisamment bonne pour servir aux internautes.
Lorsque quelqu’un effectue une recherche, les moteurs de recherche parcourent leur index pour rechercher un contenu pertinent, puis ordonne ce contenu dans l’espoir de répondre à la requête de l’internaute. Cet ordre de résultats de recherche par pertinence est appelé classement. En général, vous pouvez supposer que plus un site Web est classé, plus le moteur de recherche estime que ce site est lié à la requête.
Il est possible de bloquer les robots des moteurs de recherche sur une partie de votre site ou de demander aux moteurs de recherche d’éviter de stocker certaines pages dans leur index. Bien qu’il puisse y avoir des raisons à cela, si vous souhaitez que votre contenu soit trouvé par les chercheurs, vous devez d’abord vous assurer qu’il est accessible aux robots d’exploration et qu’il est indexable. Sinon, c’est comme invisible.
En SEO, tous les moteurs de recherche ne sont pas égaux. De nombreux débutants s’interrogent sur l’importance relative de certains moteurs de recherche. La plupart des gens savent que Google détient la plus grande part de marché, mais quelle est l’importance d’optimiser pour Bing, Yahoo et d’autres? La vérité est que, malgré l’existence de plus de 30 moteurs de recherche majeurs, la communauté SEO ne prête vraiment attention qu’à Google. Pourquoi ? La réponse courte est que Google est l’endroit où la grande majorité des gens recherchent sur le Web. Si nous incluons Google Images, Google Maps et YouTube (une propriété de Google), plus de 90% des recherches sur le Web ont lieu sur Google, soit près de 20 fois plus que Bing et Yahoo.
Crawling : les moteurs de recherche peuvent-ils trouver votre site?
Vous devez vous assurer que votre site est analysé et indexé pour pouvoir figurer dans les SERPs. Tout d’abord, vous pouvez vérifier le nombre et les pages de votre site Web qui ont été indexées par Google en utilisant « site: votredomaine.com », un opérateur de recherche avancée.
Le nombre de résultats affichés par Google n’est pas exact, mais il vous donne une idée précise des pages indexées sur votre site et de leur affichage dans les résultats de recherche.
Pour des résultats plus précis, surveillez et utilisez le rapport de couverture d’index dans la console de recherche Google. Vous pouvez vous inscrire pour un compte Google Search Console gratuit si vous n’en avez pas actuellement. Avec cet outil, vous pouvez, entre autres, soumettre des sitemaps pour votre site et contrôler le nombre de pages soumises à l’index Google.
Si vous n’apparaissez nulle part dans les résultats de la recherche, en voici les causes possibles :
- Votre site est nouveau et n’a pas encore été analysé par les google bots.
- Votre site n’a pas de liens provenant d’autres sites.
- La navigation de votre site empêche le robot de l’explorer efficacement. Par exemple : le menu en JS.
- Votre htaccess bloque certains robots.
- Votre site a été pénalisé par Google pour des tactiques de spam.
Si votre site ne répond à aucune de ces options, vous pouvez toujours tenter la démarche de soumettre votre sitemap XML dans la console de recherche Google ou en soumettant manuellement des URL individuelles à Google.
Les moteurs de recherche peuvent-ils voir l’ensemble de votre site ?
Un moteur de recherche peut parfois trouver des parties de votre site en explorant, mais d’autres pages ou sections peuvent être masquées pour une raison ou une autre (par exemple, vos pages de back office). Il est important de s’assurer que les moteurs de recherche sont en mesure de découvrir tout le contenu que vous souhaitez indexer, et pas seulement votre page d’accueil.
Les bonnes questions à se poser sont les suivantes :
- Votre contenu est-il caché derrière des formulaires de connexion?
- Si vous demandez aux utilisateurs de se connecter, de remplir des formulaires ou de répondre à des enquêtes avant d’accéder à certains contenus, les moteurs de recherche ne verront pas ces pages protégées. Un robot ne va certainement pas se connecter.
- Vous utilisez des formulaires de recherche?
- Les robots ne peuvent pas utiliser les formulaires de recherche. Certaines personnes pensent que si elles placent un champ de recherche sur leur site, les moteurs de recherche pourront trouver tout ce que leurs visiteurs recherchent.
- Le texte est-il caché dans un contenu non textuel?
- Les formulaires multimédias non textuels (images, vidéo, GIF, etc.) ne doivent pas être utilisés pour afficher le texte que vous souhaitez indexer. Bien que les moteurs de recherche améliorent la reconnaissance des images, rien ne garantit qu’ils seront en mesure de le lire et de le comprendre pour le moment. Il est toujours préférable d’ajouter du texte dans la balise <ALT> de votre image.
- Les moteurs de recherche peuvent-ils suivre la navigation de votre site?
- Tout comme un robot d’exploration doit découvrir votre site via des liens provenant d’autres sites, il doit disposer d’un chemin de liens sur votre propre site pour le guider d’une page à l’autre. Si vous avez une page que vous souhaitez que les moteurs de recherche trouvent, mais qu’elle n’est liée à aucune autre page, elle est invisible. De nombreux sites commettent l’erreur critique de structurer leur navigation de manière inaccessible aux moteurs de recherche, ce qui nuit à leur capacité à figurer dans les résultats de recherche.
Voici les erreurs de navigation courantes pouvant empêcher les robots d’exploration de voir tout votre site :
- Avoir une navigation mobile qui montre des résultats différents de ceux de la navigation sur votre bureau
- Tout type de navigation dont les éléments de menu ne figurent pas dans le code HTML, tels que les navigations activées par JavaScript. Google s’est beaucoup amélioré dans l’exploration et la compréhension de Javascript, mais ce n’est toujours pas un processus parfait. Le moyen le plus sûr de s’assurer que quelque chose est trouvé, compris et indexé par Google est de le placer dans le code HTML.
- La personnalisation, ou l’affichage d’une navigation unique vers un type de visiteur spécifique par rapport à d’autres, peut sembler masquer un robot d’exploration de moteur de recherche.
- Oublier de créer un lien vers une page principale de votre site Web via votre navigation – rappelez-vous, les liens sont les chemins que les robots d’exploration suivent sur les nouvelles pages!
Il est essentiel que votre site Web dispose d’une navigation claire et de structures de dossiers URL utiles.
L’architecture de l’information
L’architecture de l’information est la pratique consistant à organiser et à étiqueter le contenu sur un site Web pour améliorer son efficacité. La meilleure architecture d’information est intuitive, ce qui signifie que les utilisateurs ne devraient pas mener une réflexion poussée pour parcourir votre site Web ou trouver ce qu’ils souhaitent.
Votre site devrait également avoir une page utile 404 (page introuvable) lorsqu’un visiteur clique sur un lien mort ou tape une URL par erreur. Les meilleures pages 404 permettent aux utilisateurs de cliquer sur votre site pour ne pas rebondir simplement parce qu’ils ont tenté d’accéder à un lien inexistant.
Dites aux moteurs de recherche comment analyser votre site :
- En plus de vous assurer que les robots d’exploration peuvent atteindre vos pages les plus importantes, il est également important de noter que vous ne souhaitez pas que des pages de votre site soient trouvées sur votre site. Celles-ci peuvent inclure des éléments tels que les anciennes URL ayant peu de contenu, les URL dupliquées (telles que les paramètres de tri et de filtrage pour le commerce électronique), les pages de codes promotionnels spéciales, les pages de transfert ou de test, etc.
- Le blocage des pages à partir des moteurs de recherche peut également aider les robots d’exploration à hiérarchiser vos pages les plus importantes et à optimiser votre budget d’analyse (le nombre moyen de pages qu’un robot du moteur de recherche analyse sur votre site).
- Les directives de Crawl vous permettent de contrôler ce que Googlebot doit analyser et indexer à l’aide d’un fichier robots.txt, d’une balise Meta, d’un fichier sitemap.xml ou de la console de recherche Google.
Les fichiers Robots.txt
Les fichiers Robots.txt sont situés dans le répertoire racine des sites Web (ex. Votredomaine.com/robots.txt) et suggèrent les parties de votre site que les moteurs de recherche doivent et ne doivent pas explorer via des directives robots.txt spécifiques. Ceci est une excellente solution lorsque vous essayez de bloquer les moteurs de recherche à partir de pages non privées sur votre site.
Vous ne voudriez pas empêcher les pages privées / sensibles d’être explorées ici car le fichier est facilement accessible par les utilisateurs et les robots.
Voici une astuce :
Si Googlebot ne trouve pas de fichier robots.txt pour un site (code d’état HTTP 40X), il procède à l’analyse du site.
Si Googlebot trouve un fichier robots.txt pour un site (code d’état HTTP 20X), il se conformera généralement aux suggestions et procédera à l’analyse du site.
Si Googlebot ne trouve pas de code d’état HTTP 20X ou 40X (ex. Une erreur de serveur 501), il ne peut pas déterminer si vous avez un fichier robots.txt ou non et ne pas explorer votre site.
Meta directives
Les deux types de directives meta sont la balise meta robots (plus communément utilisée) et la balise x-robots. Chacune fournit aux robots d’exploration des instructions plus détaillées sur la manière d’analyser et d’indexer le contenu d’une URL.
La balise x-robots offre plus de flexibilité et de fonctionnalité si vous souhaitez bloquer les moteurs de recherche à grande échelle, car vous pouvez utiliser des expressions régulières, bloquer des fichiers non HTML et appliquer des balises noindex à l’échelle du site.
Ce sont les meilleures options pour bloquer les URL plus sensibles, privées des moteurs de recherche. Concernant les URL très sensibles, il est recommandé de les supprimer ou de demander une connexion sécurisée pour afficher les pages.
Voici une autre astuce concernant WordPress :
Naviguez dans Tableau de bord> Paramètres> Lecture, assurez-vous que la case « Visibilité du moteur de recherche » n’est pas cochée. Cela empêche les moteurs de recherche d’accéder à votre site via votre fichier robots.txt!
Évitez ces pièges courants et vous disposerez d’un contenu propre et analysable qui permettra aux bots d’accéder facilement à vos pages.
Une fois que vous avez vérifié que votre site a été analysé, vous devez vous assurer qu’il peut être indexé.
Le Sitemap
Un sitemap répertorie les URL de votre site que les robots peuvent utiliser pour découvrir et indexer votre contenu.
L’un des moyens les plus simples de s’assurer que Google trouve vos pages les plus prioritaires consiste à créer un fichier conforme aux normes de Google et à le soumettre via la console de recherche Google. Bien que la soumission d’un sitemap ne remplace pas la nécessité d’une bonne navigation sur le site, cela peut aider les robots d’exploration à accéder à toutes vos pages importantes.
La console de recherche Google
Certains sites (les plus courants avec le commerce électronique) rendent le même contenu disponible sur plusieurs URL différentes en ajoutant certains paramètres aux URL. Si vous avez déjà acheté en ligne, vous avez probablement réduit votre recherche via des filtres. Par exemple, vous pouvez rechercher des « chaussures » sur Amazon, puis affiner votre recherche par taille, couleur et style. Chaque fois que vous affinez, l’URL change légèrement.
Comment Google connaît-il la version de l’URL à utiliser pour les internautes? Google détermine lui-même l’URL représentative, mais vous pouvez utiliser la fonctionnalité “Paramètres d’URL” dans la console de recherche Google pour indiquer à Google comment vous souhaitez que vos pages soient traitées.
Indexation : Comment les moteurs de recherche comprennent-ils et se souviennent-ils de votre site ?
Une fois que vous avez vérifié que votre site a été analysé, vous devez vous assurer qu’il peut être indexé. Ce n’est pas seulement parce que votre site peut être découvert et analysé par un moteur de recherche qu’il sera automatiquement indexé.
L’index est l’endroit où vos pages découvertes sont stockées. Une fois qu’un robot a trouvé une page, il l’indexe dans le moteur de recherche.. Ce faisant, le moteur de recherche analyse le contenu de cette page. Toutes ces informations sont stockées dans son index.
Q&A sur l’indexation :
- Comment fonctionne l’indexation?
- Comment s’assurer que le site est intégré à cette base de données ?
- Pouvons-nous voir comment un robot d’exploration Googlebot voit mes pages ?
La version en cache de votre page reflétera un instantané de la dernière fois que Googlebot l’a explorée.
Google explore et met en cache les pages Web à différentes fréquences. Des sites plus connus tels que https://www.nytimes.com, seront explorés plus fréquemment que des sites Web moins bien connus.
Pour connaître la version mise en cache d’une page, vous pouvez cliquer sur la flèche déroulante située à côté de l’URL dans le SERP et en sélectionnant « Mise en cache ». Ou bien ajouter la commande Cache: devant l’url

Vous pouvez également afficher la version texte de votre site pour déterminer si votre contenu important est analysé et mis en cache efficacement.
- Les pages ont-elles déjà été supprimées de l’index ?
- Oui, les pages peuvent être supprimées de l’index ! Certaines des principales raisons pour lesquelles une URL peut être supprimée sont les suivantes:
- L’URL renvoie une erreur « introuvable » (4XX) ou une erreur de serveur (5XX) – Cela peut être accidentel (la page a été déplacée et une redirection 301 n’a pas été configurée) ou intentionnelle (la page a été supprimée le retirer de l’index)
- Une balise Meta noindex a été ajoutée à l’URL – Cette balise peut être ajoutée par les propriétaires du site pour demander au moteur de recherche d’ommettre la page de son index.
- L’URL a été pénalisée manuellement pour violation des directives Webmaster du moteur de recherche et, par conséquent, elle a été supprimée de l’index.
- L’URL n’a pas pu être explorée avec l’ajout d’un mot de passe requis pour que les visiteurs puissent accéder à la page.
- Oui, les pages peuvent être supprimées de l’index ! Certaines des principales raisons pour lesquelles une URL peut être supprimée sont les suivantes:
Si vous pensez qu’une page de votre site Web qui se trouvait auparavant dans l’index de Google n’apparaît plus, vous pouvez soumettre manuellement l’URL à Google en accédant à l’outil « Soumettre l’URL » dans la console de recherche. :
Classement : Comment les moteurs de recherche classent-ils les URL ?
Comment les moteurs de recherche garantissent-ils que lorsqu’une personne tape une requête dans la barre de recherche, elle obtient des résultats pertinents en retour ? Ce processus est appelé classement. Les résultats de la recherche sont classés des plus pertinents au moins pertinents pour une requête particulière.
Pour déterminer la pertinence, les moteurs de recherche utilisent des algorithmes, un processus ou une formule par lequel les informations stockées sont récupérées et classées de manière ordonnée. Ces algorithmes ont subi de nombreux changements au fil des ans afin d’améliorer la qualité des résultats de recherche. Google, par exemple, procède chaque jour à des ajustements d’algorithmes. Certaines de ces mises à jour sont des améliorations mineures de qualité, tandis que d’autres sont des mises à jour d’algorithmes de base destinées à résoudre un problème spécifique, comme Penguin.
Pourquoi l’algorithme change-t-il si souvent? Bien que Google n’en révèle pas toujours les raisons, nous savons que l’objectif de Google lors des ajustements d’algorithmes est d’améliorer la qualité globale de la recherche. C’est pourquoi, en réponse aux questions de mise à jour de l’algorithme, Google répondra par quelque chose du genre: «Nous effectuons des mises à jour de qualité à tout moment». Lignes directrices ou recommandations pour les évaluateurs de qualité de recherche, les deux sont très révélatrices en termes de ce que veulent les moteurs de recherche.

Les moteurs de recherche ont toujours voulu fournir des réponses utiles aux questions des internautes dans les formats les plus utiles (Google Maps, Shopping, Texte…).
Si cela est vrai, alors pourquoi semble-t-il que le référencement est différent aujourd’hui, par rapport aux années précédentes ?
- Les moteurs de recherches ressemblent à quelqu’un apprenant une nouvelle langue. Au début, leur compréhension de la langue est très rudimentaire. Au fil du temps, leur compréhension commence à s’approfondir et ils apprennent la sémantique: la signification du langage et la relation entre les mots et les phrases. Finalement, avec suffisamment de pratique, l’élève connaît suffisamment bien la langue pour comprendre les nuances et est capable de répondre à des questions, même vagues ou incomplètes. Cela fait peur non ?
Lorsque les moteurs de recherche commençaient à peine à apprendre notre langue, il était beaucoup plus facile de jouer avec le système en utilisant des astuces et des tactiques qui vont à l’encontre des recommandations de qualité. Par exemple :
- Prenez le “bourrage” de mots clés, par exemple. Si vous voulez classer un mot-clé particulier comme « blagues drôles », vous pouvez ajouter les mots « blagues amusantes » à votre page et la rendre sur-optimisé, dans l’espoir d’améliorer votre classement pour ce terme. Ce qui donnerait :
- “Bienvenue sur le site des blagues drôles ! Nous racontons les blagues les plus drôles au monde. Les blagues drôles sont amusantes et folles. Votre drôle de blague vous attend. Asseyez-vous et lisez des blagues drôles parce que les blagues peuvent vous rendre heureux et plus drôle. Quelques blagues amusantes préférées”
Cette tactique a permis aux utilisateurs de vivre de terribles expériences et, au lieu de rire de blagues amusantes, les gens ont été bombardés par un texte ennuyeux et difficile à lire. Cela a fonctionnait dans le passé, mais ce n’est jamais ce que les moteurs de recherche voulaient aujourd’hui le “content spamming” ou “content bombing” est très facilement repéré par les google bot et est fortement pénalisé !
Le rôle des liens dans le référencement
Les liens sont :
- Des backlinks ou « liens entrants » qui sont des liens provenant d’autres sites Web qui pointent vers votre site Web
- Des liens internes qui sont des liens sur votre propre site qui pointent vers vos autres pages (sur le même site).
Les liens ont historiquement joué un grand rôle dans le référencement. Très tôt, les moteurs de recherche avaient besoin d’aide pour déterminer quelles URL étaient plus fiables que d’autres pour les aider à déterminer comment classer les résultats de recherche. Le calcul du nombre de liens pointant vers un site donné les a aidés à le faire.
Le PageRank (qui fait partie de l’algorithme de base de Google) est un algorithme d’analyse de liens nommé en l’honneur de l’un des fondateurs de Google, Larry Page. PageRank estime l’importance d’une page Web en mesurant la qualité et la quantité de liens pointant vers elle. L’hypothèse est que plus une page Web est pertinente, importante et fiable, plus elle aura de liens.
Plus vous avez de backlinks naturels sur des sites Web de haut niveau (fiables), meilleures sont vos chances de se classer plus haut dans les résultats de recherche.
Le rôle du contenu dans le référencement
On en revient toujours au contenu n’est ce pas ? Les liens seraient vides de sens sans contenu. Le contenu concerne tout ce qui est destiné à être consommé par les internautes. Il contient des vidéos, de l’image et évidemment, du texte.
Si les moteurs de recherche sont des machines à réponses, le contenu est le moyen par lequel les moteurs fournissent ces réponses.
Chaque fois que quelqu’un effectue une recherche, il y a des milliers de résultats possibles, alors comment les moteurs de recherche décident-ils quelles pages l’ internaute va trouver utiles? Le classement de votre page pour une requête donnée va être en grande partie déterminée par la pertinence du contenu par rapport à la requête. En d’autres termes, cette page correspond-elle aux mots recherchés et aide-t-elle à accomplir la tâche que l’internaute tentait d’accomplir?
En raison de l’accent mis sur la satisfaction des utilisateurs et la réalisation des tâches, il n’y a pas de critères stricts sur la longueur de votre contenu, le nombre de fois qu’il doit contenir un mot clé ou ce que vous placez dans vos balises d’en-tête. Tous ceux-ci peuvent jouer un rôle dans la qualité de la recherche, mais l’accent devrait être mis sur les utilisateurs qui liront le contenu.
Aujourd’hui, avec des centaines de critères de classement, en voici 3 pertinents :
- Des liens vers votre site Web
- Du contenu sur la page (contenu de qualité conforme à l’intention d’un internaute)
- RankBrain
Qu’est-ce que RankBrain ?
RankBrain est le composant d’apprentissage automatique de l’algorithme de base de Google. L’apprentissage automatique est un programme informatique qui continue d’améliorer ses prévisions au fil du temps grâce à de nouvelles observations et à de nouvelles données de formation. En d’autres termes, il s’agit toujours d’apprendre, et comme il est toujours apprenant, les résultats de recherche devraient s’améliorer constamment.
Étant donné que Google continuera de tirer parti de RankBrain pour promouvoir le contenu le plus pertinent et le plus utile, nous devons plus que jamais nous efforcer de répondre aux attentes des internautes. Fournissez les meilleures informations et expériences possibles aux internautes susceptibles d’arriver sur votre page pour performer dans le domaine du RankBrain.
Métriques d’engagement: corrélation, causalité ou les deux?
Avec les classements de Google, il est très probable que les métriques d’engagement impliquent une corrélation partielle et une causalité partielle.
Lorsque nous parlons de mesures d’engagement, nous entendons des données qui représentent la manière dont les internautes interagissent avec votre site à partir des résultats de recherche. Cela inclut des choses comme:
- Clics (visites de la recherche)
- Heure sur la page (temps passé par le visiteur sur une page avant de le quitter)
- Taux de rebond (le pourcentage de toutes les sessions du site Web sur lesquelles les utilisateurs ont consulté une seule page)
- Pogo-sticking (cliquer sur un résultat organique puis retourner rapidement au SERP pour choisir un autre résultat)
De nombreux tests ont indiqué que les paramètres d’engagement étaient en corrélation avec un classement plus élevé, mais la causalité a été vivement débattue :
- Est-ce que de bons paramètres d’engagement indiquent uniquement des sites hautement classés ?
- Ou les sites sont-ils hautement classés parce qu’ils possèdent de bons paramètres d’engagement ?
Bien qu’ils n’aient jamais utilisé le terme « signal de classement direct », Google a clairement indiqué qu’ils utilisaient absolument les données de clic pour modifier le SERP pour des requêtes particulières.
Selon l’ancien chef de la qualité de la recherche chez Google, Udi Manber:
« Le classement lui-même est affecté par les données de clic. Si nous découvrons que, pour une requête particulière, 80% des personnes cliquent sur # 2 et que 10% seulement cliquent sur # 1, après un certain temps, nous pensons que le numéro 2 est celui que les gens veulent, alors nous le changerons.»
Un autre commentaire de l’ancien ingénieur Google, Edmond Lau, corrobore ceci:
«Il est évident que tout moteur de recherche raisonnable utiliserait les données de clic sur ses propres résultats pour obtenir un classement afin d’améliorer la qualité des résultats de recherche. Les mécanismes réels d’utilisation des données de clics sont souvent propriétaires, mais il est évident que Google utilise des données de clics avec ses brevets sur des systèmes tels que les éléments de contenu soient ajustés en fonction de la position du résultat.”
Étant donné que Google doit maintenir et améliorer la qualité des recherches, il semble inévitable que les mesures d’engagement soient plus que corrélées, mais il semblerait que Google ne considère pas les métriques d’engagement comme un « critère de classement ».
Divers tests ont confirmé que Google ajusterait l’ordre SERP en réponse à l’engagement des internautes:
- Un test en 2014 a abouti à ce qu’un résultat en position n ° 7 est passé à la première place après avoir invité environ 200 personnes à cliquer sur l’URL du SERP. Il est intéressant de noter que l’amélioration du classement semble être isolée par rapport à l’emplacement des personnes ayant visité le lien. La position de classement a grimpé aux États-Unis, où de nombreux participants se trouvaient, alors qu’elle restait plus basse sur la page de Google Canada, Google Australie.
- La comparaison de Larry Kim des pages supérieures et du temps passé moyen avant et après RankBrain semblait indiquer que le composant d’apprentissage automatique de l’algorithme de Google abaissait la position des pages sur lesquelles les gens ne passaient moins de temps. Donc plus les internautes passent de temps sur votre page sans revenir au SERP et plus votre position a de chances d’augmenter !
Étant donné que les indicateurs d’engagement des utilisateurs sont clairement utilisés pour ajuster la qualité des SERP et que les changements de position de classement constituent une part importante pour tout référenceur, il est prudent de dire que votre agence SEO ou votre responsable SEO doivent optimiser les KPIs d’engagement des internautes.
L’engagement ne modifie pas la qualité objective de votre page Web, mais elle a une valeur pour les internautes par rapport aux autres résultats de cette requête. C’est pourquoi, sans modification de votre page ou de ses backlinks, le classement pourrait diminuer si les comportements des internautes indiquent qu’ils préfèrent les autres pages.
En termes de classement des pages Web, les mesures d’engagement agissent comme un vérificateur de faits. Les facteurs objectifs, tels que les liens et le contenu, classent tout d’abord la page, puis les mesures d’engagement aident Google à s’adapter si ce n’est pas le cas.
L’évolution des résultats de recherche
Lorsque les moteurs de recherche manquaient de sophistication, le terme 10 Blue links a été inventé pour décrire la structure plate du SERP. À chaque fois qu’une recherche était effectuée, Google renvoyait une page contenant 10 résultats organiques, chacun au même format. Puis, Google a commencé à ajouter des résultats dans de nouveaux formats sur ses pages de résultats de recherche. Certaines de ces fonctionnalités SERP incluent comme par exemple :
- Annonces payées (Adwords)
- Extraits ou Rich Snippet
- Les gens demandent aussi, cherchent (Recherches Associés aujourd’hui)
- Résultat de recherche local (Google Maps)
- Google Knowledge Panel (avec l’ensemble des informations sur un lieu par exemple)
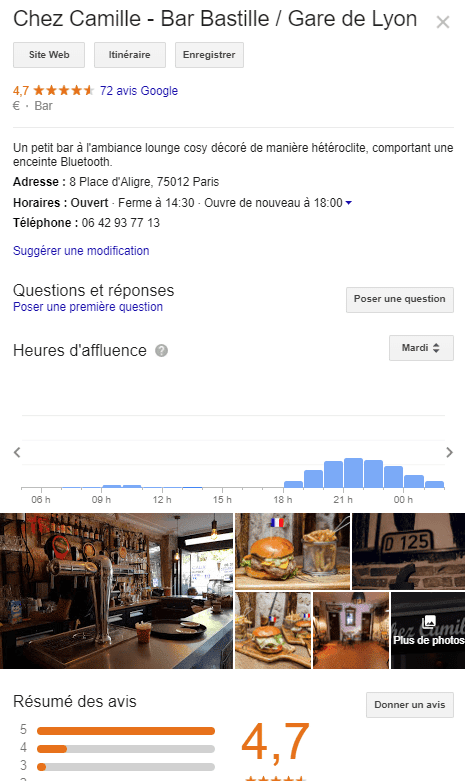
Google en ajoute de nouvelle “features” régulièrement améliore la qualité de ses résultats. L’ajout de ces fonctionnalités a provoqué une panique initiale pour deux raisons principales :
- D’une part, nombre de ces caractéristiques ont entraîné une baisse des résultats organiques sur le SERP classique “10 blue links”.
- D’autres part car moins d’internautes cliquent sur les résultats organiques, car le SERP lui-même répond à davantage de questions.
Alors, pourquoi Google agirait ainsi ? Pour améliorer l’expérience de recherche. Le comportement de l’utilisateur indique que certaines requêtes sont mieux satisfaites par différents formats de contenu. Notez que les différents types de fonctionnalités SERP correspondent aux différents types de requêtes.
- Intention de requête
- Fonction SERP possible déclenchée
- Requête Informative (définition…)
- Rich Snippet en tête (nombre d’étoile d’un hotêl, nom de l’écrivain…)
- Informatif avec une réponse (Q&A)
- Graphique de connaissances / Réponse instantanée
- Recherche Locale
- Google Maps monde
- Transactionnel (Comparer iphone X et XR)
- Achats
Des réponses peuvent être fournies aux internautes dans un large éventail de formats et que la structure de votre contenu peut avoir une incidence sur le format de recherche.
Recherche localisée
Un moteur de recherche comme Google possède son propre index propriétaire des listes d’entreprises locales, à partir duquel il crée des résultats de recherche locaux.
Pour le référencement local pour une entreprise disposant d’un site physique que les clients peuvent visiter (ex: dentiste) ou pour une entreprise qui se rend chez leurs clients (ex: plombier), assurez-vous de réclamer, vérifier et optimiser le Google My Business de cette entreprise.
En ce qui concerne les résultats de recherche localisés, Google utilise trois facteurs principaux pour déterminer le classement:
- Pertinence
- Distance
- Importance
La pertinence est la mesure dans laquelle une entreprise locale correspond à ce que recherche l’internaute. Pour vous assurer que l’entreprise a agit de manière à être pertinent pour les internautes, veillez à ce que les informations de l’entreprise soient correctement remplies.
Google utilise votre géolocalisation pour mieux adapter les résultats locaux. Les résultats de la recherche locale sont extrêmement sensibles à la proximité, qui fait référence à l’emplacement de l’internaute et / ou à l’emplacement spécifié dans la requête (si l’internaute en a inclus un).
Les résultats de recherche organiques sont sensibles à la localisation de l’internaute, mais rarement aussi prononcés que dans les résultats de recherche locale.
En raison de son importance, Google cherche à récompenser les entreprises bien connues dans le monde réel. En plus de la notoriété hors ligne d’une entreprise, Google se penche également sur certains facteurs en ligne pour déterminer le classement local, tels que:
- Avis : le nombre d’avis Google reçus par une entreprise locale et le sentiment de ces avis ont un impact notable sur leur capacité à classer les résultats locaux.
- Citations : une «référence d’entreprise» ou une «fiche d’entreprise» est une référence Web à un d’entreprise locale (nom, adresse, numéro de téléphone) sur une plate-forme connue (Yelp, TripAdvisor etc.) . Les classements locaux sont influencés par le nombre et la cohérence des citations d’entreprises locales. Google extrait les données d’un large éventail de sources pour garnir en permanence son index des entreprises locales. Lorsque Google trouve plusieurs références cohérentes au nom, à l’emplacement et au numéro de téléphone d’une entreprise, cela renforce la « confiance » de Google dans la validité de ces données. Google peut donner un degré de confiance supérieur à cette entreprise. Google utilise également des informations provenant d’autres sources sur le Web, telles que des liens et des articles.
Les meilleures pratiques de référencement s’appliquent également au référencement local, car Google considère également la position d’un site Web dans les résultats de recherche organiques lors de la détermination du classement local.
Bien que Google ne le mentionne pas comme déterminant de classement local, le rôle de l’engagement ne fera que croître avec le temps. Google continue d’enrichir les résultats locaux en intégrant des données réelles telles que les temps de visite populaires et la durée moyenne des visites.
Les données locales influencent les résultats locaux. Cette interactivité entre internautes et entreprises locales est souvent plus pertinente que des informations purement statiques elles que des liens et des citations.
Étant donné que Google souhaite offrir aux internautes les meilleures entreprises locales, il est parfaitement logique qu’ils utilisent des mesures d’engagement en temps réel pour déterminer la qualité et la pertinence.
Nous espérons nous avoir éclairer sur les différentes questions sur le Crawl, l’indexabilité, le classement et sur le fonctionnement global de l’algorithme de Google. Après ces étapes n’oubliez pas d’optimiser votre contenu pour créer plus d’engagement.
Si vous souhaitez en découvrir plus sur le Contenu n’hésitez pas à télécharger notre E-book sur le Growth Marketing : ICI

